Slow connect (TCP retransmits) via NodePort #76699
Comments
|
/sig network |
|
/triage unresolved Comment 🤖 I am a bot run by @vllry. 👩🔬 |
|
Is the route from haproxy2 to 12328 and from haproxy2 to 456 different? |
|
@yanghaichao12 routes absolutelly the same. Both haproxies in same /24 network. All kubernetes nodes in same /24 network. |
|
Also kubernetes nodes connected to network with lacp bonds. To check if problem in bond balancing I've disassemblied bond on 8 node and connected with one interface. But nothing changed. |
|
have you check conntrack numbers,like this: cat /proc/sys/net/netfilter/nf_conntrack_max
cat /proc/sys/net/netfilter/nf_conntrack_count |
|
@yanghaichao12 yes, these numbers are monitored. |
|
have you check conntrack state? are there any "INVALID" connection? or what's the result: cat /proc/sys/net/ipv4/netfilter/ip_conntrack_tcp_be_liberal |
Yes, there are many invalid connections according to Also there are many
Tried both net.netfilter.nf_conntrack_tcp_be_liberal 0 and 1. At the moment nodes 1-7 with net.netfilter.nf_conntrack_tcp_be_liberal=1 and node 8 with net.netfilter.nf_conntrack_tcp_be_liberal=0. And seems it doesn't affect tcp retrans rate. |
|
This smells like more of the same kernel bug discussed in that article. Are you with XING Engineering? Maybe I missed it, but I did not notice where the article said the latest flannel would fix the problem. As far as iptables is concerned, that article said the authors created a patch that was "merged (not released)". Do you know whether that patch is in iptables 1.6.2? Have you tried printing out the relevant iptables rules? I am not real familiar with the iptables code, but it looks like that patch includes a change to the printing that exhibits the full random setting when/where it is applied. To confirm my understanding: your problem is slow connections and HAProxy reports redispatching (not retransmissions), right? Have you tried simplifying the situation? My suspicion is drawn to the masquerading that is part of the NodePort Service functionality; HAProxy is not an essential part of it. It looks like you are describing synthetic tests applied in a lab environment. Have you tried pointing your load generator directly at a cluster node? Have you tried capturing packets and looking to see where the SYN goes missing? |
|
Also, if I understand that kernel bug correctly, it is more likely to bite the fewer the destinations. Does your problem occur more frequently when there are fewer services involved? It may be easier to diagnose if only one service is involved. Has the fundamental kernel bug (the race condition) been fixed? If so, could you try a kernel with the fix? Could you be running out of ports? |
|
@MikeSpreitzer patch is in iptables 1.6.2. I've checked flannel's repo and found Currently node 8 is only node in cluster with iptables 1.6.2 + latest flannel and I see Yes, our problem is slow connections from HAProxy. Retransmission and redispatches in HAProxy, as I understand, near same things. The difference: retransmission - retry on same server, redispatch - retry on other server in group. It is not a lab with load generator. It is our live traffic and we cannot reduce service count. Tried to capture traffic between nodes and HAProxies and saw TCP retransmits, but cannot find root cause since I'm not so strong in low level networking. Also tried to capture traffic on nodes, but it is much harder to do this in NATed-bridged-namespaced environment. Cannot find information about current state of kernel bug. |
|
At the moment we stabilized situation. Enabled keep-alive everywhere we can (clients, loadbalancers, microsevices) and no retransmits anymore. So I think we are really were out of ports somewhere (namespaced networks?) but cannot catch this. Any method to monitor POD networks to avoid such situation? |
|
It looks like you do not have The first rule listed, for KUBE-POSTROUTING, is the one that does the masquerading for an inbound request to a NodePort service (as well as for other cases) |
|
Also, the prospect of running out of ports for masquerading concerns me. Can you outline the calculation? How large is the rage of port numbers used for this purpose? The load is spread among 8 nodes, right? If I understand correctly, on the first Node it hits the initial SYN packet's source NAT is done after its destination NAT; that means the number of endpoints, rather than the number of services, is the relevant quantification of that side. Does conntrack re-use a source port number for different destinations? How long does each connection last? How long does conntrack retain the association after the last packet is seen? What happens if you do run out of ports? Is an error logged anywhere? |
|
@zigmund can you get any vulable information in system log?like dmesg something |
This rule is added by kubelet (or kube-proxy?) and I found only one relevant closed ticket: #62628
Right.
Yes. DNAT is PREROUTING action while SNAT is POSTROUTING.
Conntrack can handle same src-ip:scr-port since all combination src-ip:scr-port:dst-ip:dst-port is unique. I see src-ip:src-port duplicates via
Some connections is out case are long lasting (websockets) and some not. I believe connection tracking is controlled by sysctls: We have not changed these values since conntrack count far from max. First thing I've done when we found the problem - lowered net.ipv4.tcp_fin_timeout to 15s and extended local port range to 1024-65535 on proxies and 32768-65535 on nodes. It helped a lot, but not solved problem completelly. After enabling keep-alive (cut out Unfortunately I started to record node's conn count after changes and that metrics are useless in current situation. But I can say, that keep-alive redused TIME-WAIT conn count significantly, from thouthands to handreds. Conntrack conns also gone down from ~100k peak to ~60k. Also we identified slow connections with high RPS from POD to kube service. For test I changed port range to 1024-65535 in pod via privileged init container and that solved the problem. At the moment we are patching our microservices to enable keep-alive when microservice acting as client. |


|
According to formula for max outgoing requests per second: And I don't understand why extending port range in out case helped a lot. For example, we have pretty loaded serviceA (3 POD replica) exposed via hostPortA on 8 nodes. One haproxy sending up to 500 RPS spreaded to 8 nodes. So it will be 470 / 8 = ~60 RPS. Far from limit. Similiar situation on nodes' side. 60 RPS from each node spreaded to 3 endpoints...... I inspected connections on haproxies' side, nodes' side, PODs' side. Also we had retransmits with less loaded services - 30..50 RPS. |
|
@yanghaichao12 checked dmesg, kubelet, kube-proxy, flannel logs and there is no interesting information. :( |
|
@zigmund could you reproduce it in lab? i think it's easy because you said it occurred even with 30..50 RPS, right? and do you consider testing it in different kernel? |
|
@yanghaichao12 less loaded services affected too, but only when overall cluster load is high. I'll try to reproduce in lab with load generator. |
|
@zigmund so, Have you ever suspected it's probleme about HAproxy? |
|
Or, from the other direction: can you apply a load generator directly to a node & service NodePort, and get the same result, thus proving that HAProxy is not a critical part of the story? |
|
So you certainly are vulnerable to the conntrack collision problem, since the relevant iptables rule does not include |
|
@zigmund what is your haproxy configuration for |
Currently we collecting almost everything can get from haproxy stats. For example, server stats: |
|
/remove-triage unresolved |
|
I think the first thing to do is make kube-proxy add |
|
Thanks, @MikeSpreitzer Is there any workaround? I've tried to add rules manually to KUBE-POSTROUTING chain, but seems kube-proxy overwrites my rules. |
|
I've made custom chain with --random-fully masquerade and inserted rule to jump there before KUBE-POSTROUTING. Alse made this trick with docker's masquerade rule. According to iptables' counters packets goes to correct chain. Monitored for few hours and didn't see any difference. :( |
|
Yes, kube-proxy maintains the rules in the KUBE-POSTROUTING chain. I suppose you mean that you are still seeing SYN drops. Are you also looking at the insert_failed counter from This may be grasping at straws, but I note that your experiment did not remove the KUBE-POSTROUTING chain. Is it possible that in your experiment the KUBE-POSTROUTING chain is being used as well a the KUBE-POSTROUTING-CUSTOM chain? Do you need the rules in the POSTROUTING chain after the jump to KUBE-POSTROUTING-CUSTOM? If not, can you try inserting a |
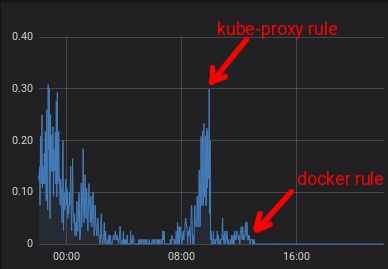
Almost no insert_failed after I enabled random-fully on kube-proxy and docker rules. See pic. First big drop of insert_failed/sec after I added kube-proxy's rule, second drop to zero is for docker's rule.
I've tried to remove this rule, but kube-proxy recreates it almost instantly.
Packet goes to correct chain. MASQUERADE is terminating target, matched packet will not go to other rules, no need to add RETURN. I can confirm it with iptables counters: I think random-fully made situation slightly better, but global problem is somewhere else. |

|
Oh, right, the counters you showed earlier say the same thing. What changed after 08:00 to make insert_failed/sec go up again? Why are the Docker rules involved? |
It is our native load depending on daytime. I added kube-proxy rule at ~9:30 and docker rule at ~13:00.
Since Docker have masquerade rule I decided to add random-fully to this rule too. The rule is for outgoing traffic from containers. |
|
Issues go stale after 90d of inactivity. If this issue is safe to close now please do so with Send feedback to sig-testing, kubernetes/test-infra and/or fejta. |
|
/remove-lifecycle stale |
|
/priority important-soon |
|
/milestone v1.16 |
|
no final solutions? |
|
If it's helpful https://github.blog/2019-11-21-debugging-network-stalls-on-kubernetes/ describes the approach we took at GitHub to finding and mitigating most of these network stalls. |
|
@zigmund so did our adding |
|
@danwinship But the more nodes we use - less redispatches we have overall. |

|
same problem |
1 similar comment
|
same problem |
What happened:
In out archutecture we have some kinda external (out-of-cluster) Ingress Controller, based on HAProxy + self-written scripts for Kubernetes service discovery (2 instances). ~60 Kubernetes services exposed via NodePort on 8 Kubernetes nodes. Each node runs kube-proxy in iptables mode.
Everything worked fine. But after cluster got more load (HTTP requests per second / concurrent connections), we are experiencing slow connects to services exposed via NodePort because of TCP retransmits.
For now have 4k RPS / 80k concurrent peak. TCP retransmits starts at ~1k RPS / 30k concurrent.
But most strange thing in this situation - retransmit count not same for haproxy/kube-node pair.
For example, haproxy1 have retransmits from kube-nodes 1,2,3 and 8, but haproxy2 have almost zero retransmits from that nodes. Instead haproxy2 have retransmits from kube-nodes 4,5,6 and 7. As you can see, it is like mirrored.
See attachments for clarification. HAProxy configured with 100ms connect timeout, so it redispatches connection on timeout.


What you expected to happen:
No TCP retransmits, fast connects.
How to reproduce it (as minimally and precisely as possible):
Commit 50-60 deployments + NodePort-exposed services on few nodes. Load with 1k+ RPS, 30k+ concurrent cons. Observe slow connects (1s, 3s, 6s...)
Anything else we need to know?:
Intercluster communication via flannel w/o cni in hostgw mode.
Tried different sysctls on nodes and haproxies. Tried ipvs mode and got much more TCP retransmits.
Also tried with iptables 1.6.2 with latest flanneld to fix NAT bugs according to this article: https://tech.xing.com/a-reason-for-unexplained-connection-timeouts-on-kubernetes-docker-abd041cf7e02
For test installed on kube-nodes out-of-cluster reverse-proxy to pass traffic from outside to kubernetes services and pods - no problems. Also no problems with HostPort-exposed services.
Environment:
kubectl version):Client Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.6", GitCommit:"b1d75deca493a24a2f87eb1efde1a569e52fc8d9", GitTreeState:"clean", BuildDate:"2018-12-16T04:39:52Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"} Server Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.6", GitCommit:"b1d75deca493a24a2f87eb1efde1a569e52fc8d9", GitTreeState:"clean", BuildDate:"2018-12-16T04:30:10Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}Masters: 5 x kvm VMs 16.04.6 LTS (Xenial Xerus) / 4.15.0-45-generic.
Nodes: Baremetall Supermicro Intel(R) Xeon(R) CPU E5-2695 / 128 Gb RAM
cat /etc/os-release):Prod nodes:
16.04.6 LTS (Xenial Xerus)Test node:
Debian GNU/Linux 9 (stretch)uname -a):Prod nodes:
Linux hw-kube-n1.alaps.kz.prod.bash.kz 4.15.0-45-generic #48~16.04.1-Ubuntu SMP Tue Jan 29 18:03:48 UTC 2019 x86_64 x86_64 x86_64 GNU/LinuxTest node:
Linux hw-kube-n8.--- 4.9.0-8-amd64 #1 SMP Debian 4.9.144-3.1 (2019-02-19) x86_64 GNU/LinuxMix of hard way / ansible.
Don't know if it is kube-proxy / iptables problem or maybe I'm just missing some sysctls / kernel params.
The text was updated successfully, but these errors were encountered: