ContentRicher - Enriching editorial content to address different knowledge levels
ContentRicher enables media professionals, journalists and editors, to reach a wider audience by adding additional information to articles for different target groups with different levels of knowledge.
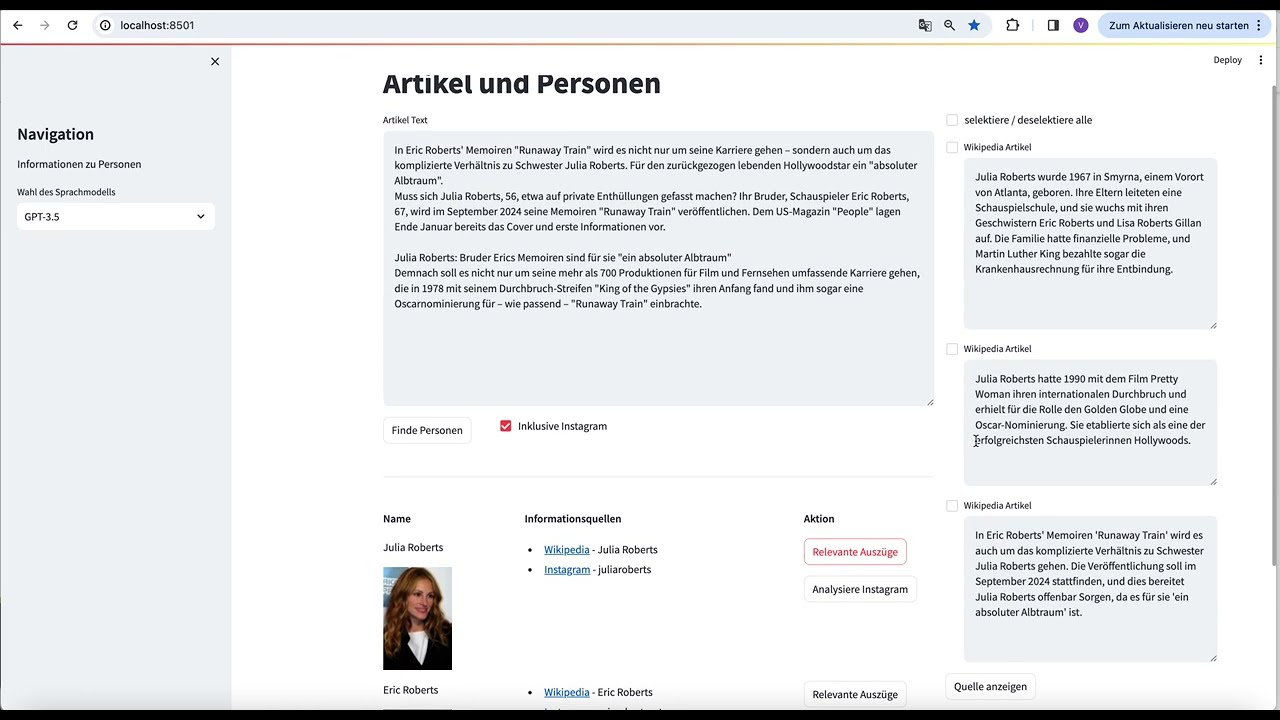
It is a web- and AI-based system that detects relevant parts in given texts that would benefit from additional explanation. It then retrieves additional information, identifies the most relevant parts and enriches the text seamlessly.
- AI-based Retrieval of facts: Based on state-of-the-art Large Language Models (choose between GPT-3.5 and Mistral) and Multimodal Models ContentRicher identifies persons in the text and retrieves relevant facts about them from Wikipedia and Instagram (from both text and images).
- Human-AI collaboration: While the presented facts are already relevant to journalists and editors in the writing process, we also offer automatic integration of the facts: The relevant facts are proposed to the user, who can then select which facts they want to automatically integrate into the text (still to be implemented).
- Userfriendly Interface: Based on Streamlit, it offers a browser-based interface, with intuitive controls and display of the results.
Click on the image to get to the video on Youtube.
Click here to see another video based on enrichting content with Instagram data:
video2
To run the app via docker, create a virtual environment with python==3.9.11 as the python version:
conda create --name [PUT YOUR ENVIROMENT NAME HERE] python=3.9.11
Activate the environment with:
conda activate [PUT YOUR ENVIROMENT NAME HERE]
Then, clone the repository:
git clone https://github.com/ContentRicher/contentricher.git
Change into the contentricher folder
cd contentricher
Then, run the docker image with:
sudo docker compose up
To run the app, create a virtual environment with python==3.9.11 as the python version:
conda create --name [PUT YOUR ENVIROMENT NAME HERE] python=3.9.11
Activate the environment with:
conda activate [PUT YOUR ENVIROMENT NAME HERE]
Clone the repository:
git clone https://github.com/ContentRicher/contentricher.git
Then change to the ./app folder
cd app/
and install the libraries from the requirements.txt via:
pip install -r requirements.txt
Change into the experiments folder
cd experiments/
Then, open the .env file in the experiments folder. You may need to press CMD + SHIFT + . to show the file. Insert your key/s in the placeholders
API_KEY = "[PUT YOUR OPENAI API KEY HERE]" (for using GPT-3.5 from OpenAI) and/or put
MISTRAL_API_KEY = "[PUT YOUR MISTRAL_API KEY HERE]" (for using the Mistral Small Model).
To add Mixtral over Groq (for faster inference), enter your Groq key, which you can obtain here: https://groq.com/
GROQ_KEY="[PUT YOUR GROQ KEY HERE]"
Similarly, for the database, insert a database name and the name and password for the admin user.
Keep host and port as is.
Insert an name and password for your testuser under POSTGRES_NORMALUSER and POSTGRES_NORMALUSERPASSWORD.
Finally, run the app from the experiments folder with:
streamlit run frontend_experiments.py
To run the analysis of the latest Instagram Posts of people mentioned in the text, you need to add your Instagram username. We provide two fields for that at runtime.
You may need to log in to your Instagram account on Firefox before using ContentRicher.
Disclaimer: Make sure you read the current Instagram / Meta terms of use and only use this feature if it agrees with them.
Currently, ContentRicher is a working prototype. We retrieve information from Wikipedia and we include information from the latest Instagram posts of the identified persons (both from text and images). This may be extended by retrieving information for different text elements (besides persons) and from different data sources.
ContentRicher is licensed under the MIT license. For more information check the LICENSE file for details.
- Media Tech Lab
media-tech-lab
