While CSRF (Client-side Request Forgery) will try to send the malicious request on the behalf of the victim, SSRF (Server-side Request Forgery) will trick server to make arbitrary requests to the hosts we want, which can be external or internal service. SSRF, in general, will cause severe impact on the server as attackers will have the ability to get access to internal networks and perform malicious actions. The picture below will give you a better understanding of how it works
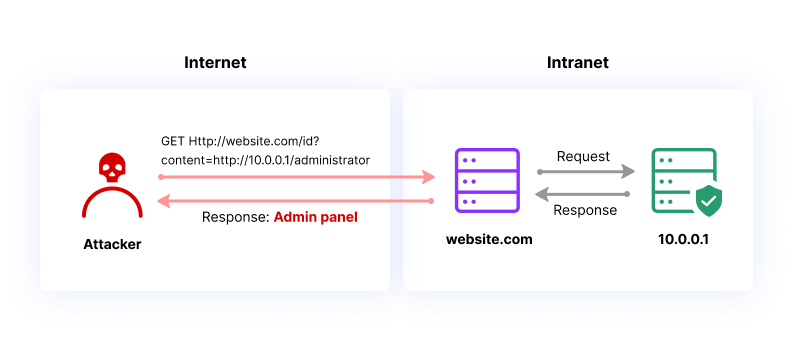
Let's imagine a scenario, there's a booking website with a functionality to check if the room is booked. When user click on Check the room, the request will look like this:
GET /check-availability?url=checkroom.com/?room_id=1 HTTP/2
Host: example.com
We notice that the server will fetch data from another server via the value of url parameter. Once the request is sent, the server we're interacting will make another request to the server that have the data of rooms (checkroom.com in this case)
GET /?room_id=1 HTTP/2
Host: checkroom.com
As usual, we cannot get access to internal service of the website, or get access to restricted area. However, the internal server will handle request coming from internal networks differently, which will often has no authentication checks because request from internals are believed to be safe. We can take advantage of this feature to discover the internal networks as well as read sensitive file of the server. For example, there's a server runs locally, we can try the change the value of url to /check-availability?url=localhost/etc/passwd. The server then make another request to localhost
GET /etc/passwd HTTP/2
Host: localhost
Because this request comes from trusted origin, then it will return the content of passwd file, then this file content will be displayed to us.
A successful SSRF attack can result in various outcomes:
- Sensitive data exfiltration: Attackers can access to file systems and read these contents
- Port scanning: SSRF also allows attackers to scan port and launch other attacks
- DOS attack: Because requests from internal networks won't be blocked, attackers can take advantage of that to flood requests and make server crashed.
- Remote Code Execution: In some situation, a chain with command injection via SSRF can also result in Remote Code Execution (RCE)
I will use 2 PortSwigger labs to demonstrate the vulnerability.

As described, there's a function to check for stock and our target is to get access to http://localhost/admin to delete user carlos.

We can try to visit any product and press the Check stock button to see what will happen.

The server retrieve stock value by requesting to another server at http%3A%2F%2Fstock.weliketoshop.net%3A8080%2Fproduct%2Fstock%2Fcheck%3FproductId%3D1%26storeId%3D1 via stockApi parameter, which is url-encoded version of http://stock.weliketoshop.net:8080/product/stock/check?productId=1&storeId=1. We can see that the server request to another server (stock.weliketoshop.net:8080). Now let's try to request to localhost/admin.


Surprisingly, the server returns the content of admin panel. We can see user carlos with delete button, so let's click on it.


It says that we're unauthorized. It is because our request comes from external sites, which will be blocked. Therefore, we need to take advantage of the stockApi value. From the above image, we can see that there's an endpoint /admin/delete?username=carlos that will delete carlos. So let's modify the stockApi value to exploit this.


Wonderful!!! We solved Lab 1. This is an easy case of SSRF. In reality, it's not easy like this to exploit SSRF, the servers tend to implement many protections to prevent attackers from exploiting this bug. In the next lab, we will discover some techniques to bypass the protection to exploit SSRF

The description tells us SSRF protections are in placed, so this lab will be a lot harder. Basically, the exploit flow is the same as lab 1, so I will directly check view stock functions and examine the request in Burpsuite.

The request is similar to lab 1. Let's try to change the url to http://localhost/admin

The error message tells that the host must be stock.weliketoshop.net, which means that the server did implement protections against SSRF, known as white-listed filter. In this SSRF tutorial of PortSwigger, they also proposed different ways to bypass whitelist input filter.
Some applications only allow inputs that match, a whitelist of permitted values. The filter may look for a match at the beginning of the input, or contained within in it. You may be able to bypass this filter by exploiting inconsistencies in URL parsing.
The URL specification contains a number of features that are likely to be overlooked when URLs implement ad-hoc parsing and validation using this method:
- You can embed credentials in a URL before the hostname, using the
@character. For example:
https://expected-host:fakepassword@evil-host
- You can use the
#character to indicate a URL fragment. For example:
https://evil-host#expected-host
You can leverage the DNS naming hierarchy to place required input into a fully-qualified DNS name that you control. For example:
https://expected-host.evil-hostYou can URL-encode characters to confuse the URL-parsing code. This is particularly useful if the code that implements the filter handles URL-encoded characters differently than the code that performs the back-end HTTP request. You can also try double-encoding characters; some servers recursively URL-decode the input they receive, which can lead to further discrepancies. You can use combinations of these techniques together.
Let's try stockApi=http://localhost@stock.weliketoshop.net and the server responded differently meaning that this url is accepted. In this case, everything before @ is considered as credentials, localhost is username in this case. Some parser are not configured properly that will make the request to localhost and ignore the remaining. Now we need to have another bypass to request to localhost but also make sure stock.weliketoshop.net in the url, and # is the solution. # in url is the fragment that allows us jump to specific parts of the web page. This is an optional feature in the url and does not affect the main components of the url. For example, if we try http://localhost#stock.weliketoshop.net, everything comes after # will be ignored.
However, when we try stockApi=http://localhost#@stock.weliketoshop.net, the server returns error.

It means that the validation worked properly, not only it checked if stock.weliketoshop.net exists in the url but also make sure that it is really the host. PortSwigger suggested that we can url-encode the characters to confuse the parser, so why don't we try it?


We successfully get access to http://localhost when we double-encode the url. This bypass is successful because the checker probably just normalize the url by decode one time instead of doing it recursively. Let's have a look at this image

When the checker in the backend decode the url, it recognizes the fragment # and ignore everything after it. Therefore, it will see localhost as the host and that's why it returned error.

In my opinion, I think that there're 2 different functions that handle the validation and perform requesting the resource separately. While the check function only perform url-decode once, which allowed us to bypass the validation, another function will do it recursively which will request to the host we control. With that idea, let's try to access the admin panel by accessing to http://localhost/admin

Unfortunately, the server only return the content of / instead of /admin. As discussed above, this is maybe because the differences between how 2 functions process the url.

when we try to append /admin at the end of the url, it works. This can be explain by this image

Finally, we see that there's an endpoint /admin/delete?username=carlos that will allow us to delete user carlos. we will use this payload to conduct the attack and solve the lab stockApi=http://localhost%2523@stock.weliketoshop.net/admin/delete?username=carlos


Tadaaa! We solved the lab. This lab is tricky cause it requires many bypasses to solve it. However, this will give us more knowledge and techniques for further testing in the real world. The end of lab 2 is also the end of today's article. I hope you will learn something useful. Happy hacking!!!!