PostgreSQL High Availability with patroni/spilo for Docker Swarm
The World's Most Advanced Open Source Relational Database
A template for PostgreSQL High Availability with Etcd, Consul, ZooKeeper, or Kubernetes
https://github.com/zalando/patroni
Highly available elephant herd: HA PostgreSQL cluster using Docker
https://github.com/zalando/spilo
You need to have a Docker Swarm cluster up and running and etcd cluster running.
You should only have PostgreSQL cluster deployed once per Docker Swarm Cluster.
You need to deploy PostgreSQL cluster along with the etcd cluster.
See https://github.com/YouMightNotNeedKubernetes/etcd for instructions on how to setup an etcd cluster.
There are many ways to run high availability with PostgreSQL; for a list, see the PostgreSQL Documentation.
Patroni is a template for high availability (HA) PostgreSQL solutions using Python. For maximum accessibility, Patroni supports a variety of distributed configuration stores like ZooKeeper, etcd, Consul or Kubernetes. Database engineers, DBAs, DevOps engineers, and SREs who are looking to quickly deploy HA PostgreSQL in datacenters - or anywhere else - will hopefully find it useful.

Before you can deploy PostgreSQL, you need to carefully plan your deployment.
- Consider how many PostgreSQL instances you want to deploy.
- Node placement for each PostgreSQL instance.
- Storage driver for the volumes.
- How much storage you want to allocate to each instance.
- etc...
Here are some useful tips to help you plan your deployment.
A node.labels.postgres label is used to determine which nodes the service can be deployed on.
The deployment uses both placement constraints & preferences to ensure that the servers are spread evenly across the Docker Swarm nodes and only ALLOW one replica per node.
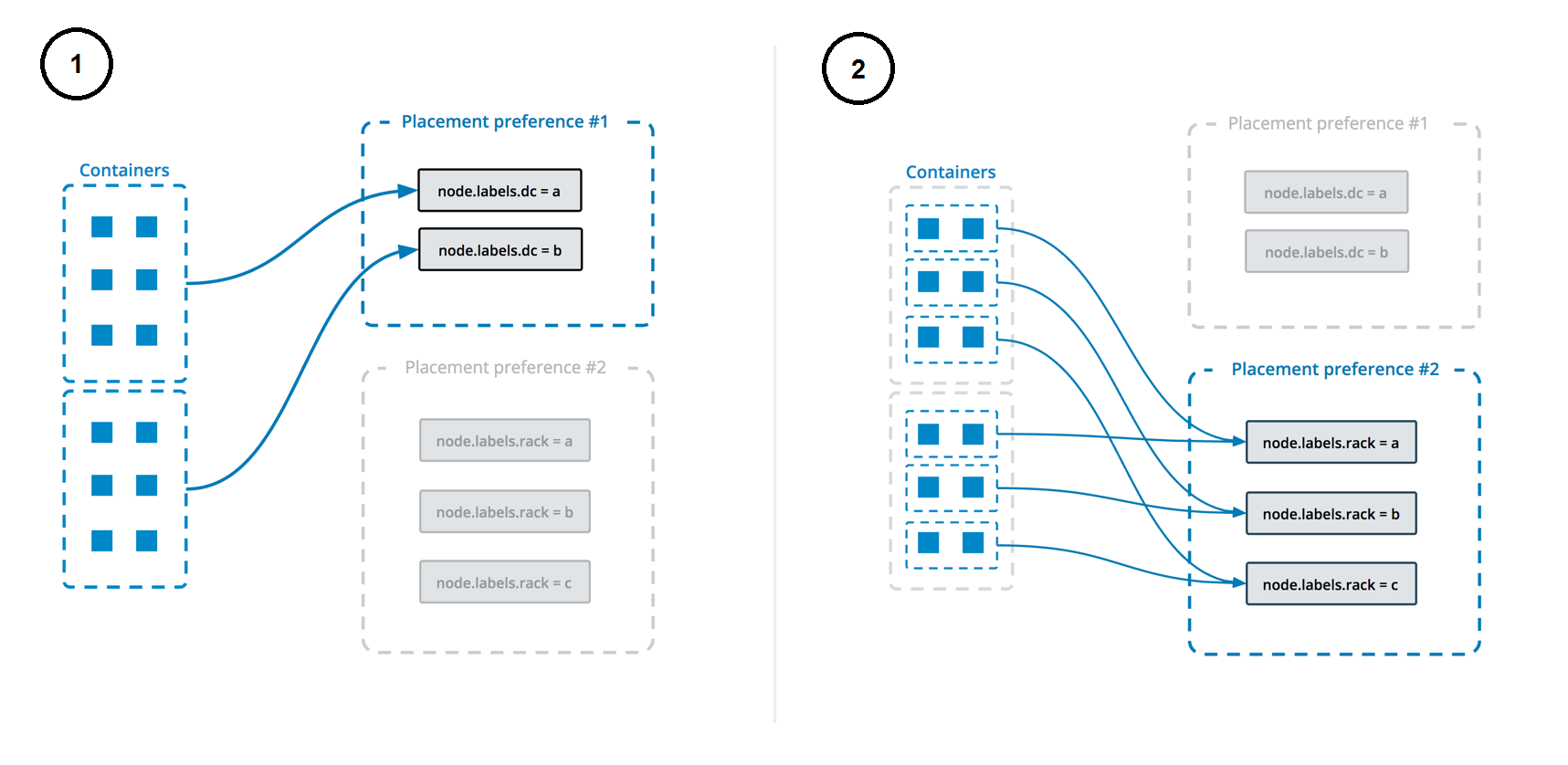
See https://docs.docker.com/engine/swarm/services/#control-service-placement for more information.
On the manager node, run the following command to list the nodes in the cluster.
docker node lsOn the manager node, run the following command to add the label to the node.
Repeat this step for each node you want to deploy the service to. Make sure that the number of node updated matches the number of replicas you want to deploy.
Example deploy service with 3 replicas:
docker node update --label-add postgres=true <node-1>
docker node update --label-add postgres=true <node-2>
docker node update --label-add postgres=true <node-3>Please configure the .env file before deploying the stack.
To deploy the stack, run the following command:
$ make deploy
# or enable pgBouncer
$ make deploy pgbouncer=trueTo destroy the stack, run the following command:
$ make destroy
-
5432: The port forpostgres_rwinstance (Primary).
Port can be configured viaPGSQL_PRIMARY_PORTenv -
5433: The port forpostgres_roinstance (Replica).
Port can be configured viaPGSQL_REPLICAS_PORTenv -
5480: The port for accessing Spilo API.
Port can be configured viaPGSQL_SPILO_PORTenv -
5484: The port for HAProxy stats.
Port can be configured viaPGSQL_STATS_PORTenv
Its creators are working on a Postgres operator that would make it simpler to deploy scalable Postgres clusters in a Kubernetes environment.
The documents now moving toward using Kubernetes, but the Spilo project is still a good reference for how to deploy Postgres in a Docker Swarm environment.
Hence the reason why this project exists. To keep the tradition going.