Graph Runtime for Heterogeneous Execution #1242
Comments
|
@zheng-da @reminisce Since they are working on subgraphs. |
|
For the first step, is there a way we can detect that whether op is registered for current target in tvm? In this case, we don't need to add an extra attribute. If this is unrealistic, then in FComputeFallback, we may want to specify for what targets this operator needs to be fallback to cpu. |
|
@tqchen, Someone already working on this? or any conflict with relay related works going on? |
|
@tqchen It seems to me that the subgraph approach currently developed in MXNet can fit well for the heterogeneous execution. |
|
@zhiics this sounds awesome, do you want to provide more details, feel free to post discussions here |
|
@tqchen The basic idea is to partition a computational graph into a bunch of subgraphs according to some rules. Each subgraph, therefore, contains a number of nodes. These subgraphs will be compiled into modules individually, potentially each one could be for a specific device. In the end, each module will be executed using tvm runtime. Any suggestions or comments will be appreciated. |
|
I see, I was thinking a more basic way, to extend the runtime a bit with a context field, and insert cross device copy, so the final evaluation still runs on a single graph, but each entry can use different context |
|
If the purpose is for executing different nodes on different devices, I think @tqchen 's method is more suitable. It would be similar to using context group in The subgraph method developed in MXNet is mostly for executing the subgraphs of a nnvm graph using different accelerators, such as TVM, MKLDNN, and TRT. Each accelerator can take an nnvm subgraph and applies operator fusion, layout conversion accordingly. |
|
@zhiics building individual modules lead to many outputs which complicates the deployment. inserting a context field make it more transparent to user. |
|
Really interesting topic! I have once developed similar mechanism in caffe for an accelerator (could be one of the fast ones in this plant currently :) ). Personally, I think it would be cool if there were generic graph for every backend device - especially when you are talking about Heterogeneous Execution. Basically, accelerator drivers only handle generic neural networks interfaces - one unified optimized graph of TVM could bring in difficulty when enabling enormous accelerators. I don't have much knowledge of TVM, neither not sure about whether TVM aims to enable different backends on one devices, but if that is the case, a generic graph solution sound cool maybe - you can perform different optimization for different backend device inside the graph. Anyway, basic solution requires less effort at this time... (ignore me, i am just balabala...) |
|
I believe @tqchen's solution should be the most suitable and (also probably the most general) one. It has been proven promising to do program slicing and synchronize data only when necessary. My question is, suppose we have a higher-level IR and its interpreter (with JIT), and this IR also supports program slicing by reusing some simple type inference system. Is it worth discussing the advantages and disadvantages between synchronizing in high-level and low-level? Thanks :) |
So is it possible for you to share more technical details about how you do these cool stuff? |
|
Thank you all for sharing. We (@yidawang @yzhliu ) also thought about @tqchen 's solution. It's a very nice and generic approach. But we think it is also helpful to keep another hierarchy for optimization and deployment on different devices. I agree that dividing into modules may lead to multiple outputs sometimes. But we could provide some wrapper to make the process of module build and deployment transparent to user. We may currently still stick to our method. However, it would be very interesting to see the other implementation. |
|
I think this task has two parts. The first task is to compile part of a graph for a particular device. I think the simplest way is to partition the graph into subgraphs so that we can reuse everything TVM has right now to compile individual subgraphs. Without partitioning, graph-level scheduling search can be difficult. |
|
I agree with @zheng-da thought on thinking about two perspectives:
I am advocating for the simple context-based method on the runtime side, regardless of how compiler can be implemented. The reason is that it keeps the current interface minimum and clean an the users. |
|
@junrushao1994 still in confidential. Also, caffe is so lightweighted that we simply feeds abstracted networks data into underlying device driver without any optimization that TVM does. The driver itself handles optimization, compiling, running. My point is, when we are talking about something like interface or heterogeneous, the abstracted description passed from high level to low level should be self-contained, which means that when you passing a so-called subgraph (or context keyword you like), the subgraph information should be no more no less - it just like another network (regardless the purpose of it). This is just like you are running a single graph context on one device. The interface is so important that it will impact all backend drivers. It will be pretty weird for a device driver knows that it has a big graph, but it should only execute part of the graph. You guys can look into Android Neural Networks API (check So, i vote for @zhiics (though i have contributed nothing to tvm...) |
|
@jackwish My understanding for this problem is that we might want to keep abstract graph for compiler so that different optimizations can be done easily for heterogeneous devices, but not necessarily for runtime. Since we might not want to execute these subgraphs individually, a wrapper to pack all subgraphs and data flow information is what we want for runtime. I think both solutions will work, but changing the runtime interface might be a cleaner way for implementation. |
|
@jackwish I am not sure if my understanding is correct. Are you referring to program slicing, like the solution in TensorFlow Swift for dispatching computation and synchronizing data between different devices? For example, the compiler knows the entire graph, which represents heterogeneous computation on several devices. The compiler simply does some heuristics or anything like type inference to figure out which part of the program should reside on which device, and dispatch this part to the corresponding device. |
|
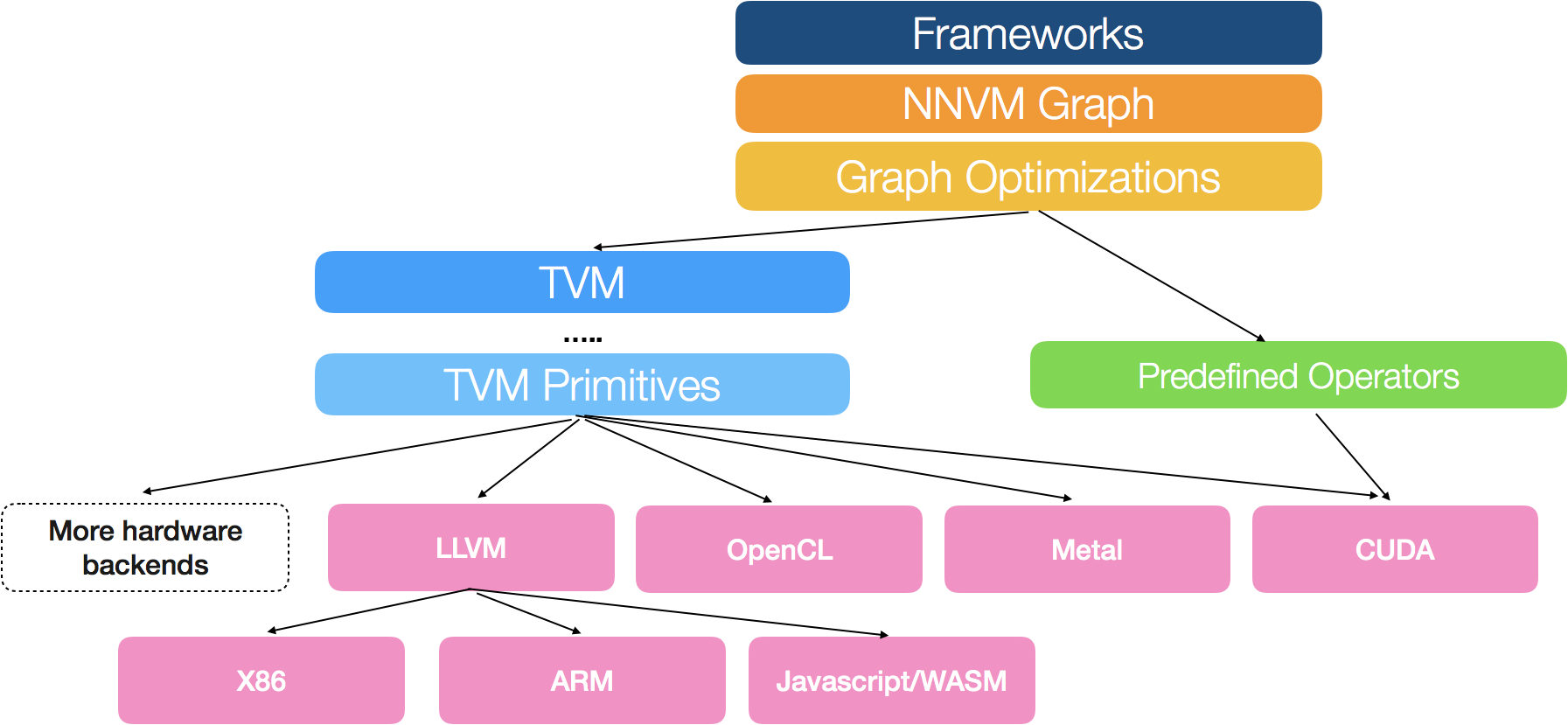
@kevinthesun Thanks for your explanation. I know exactly that TVM aims to provide generic optimization regardless the backend device, and I was very excited when I got to read TVM paper. However, when it comes to practice, especially in context of this heterogeneous execution issue, the primitives of the backend is mostly inconsistent across different devices. What I am trying to say is that, yes we can optimize IRs that finally feed to LLVM-like backend which happily takes these IR; but regarding accelerators, a driver is usually provided by the accelerator vendor - the primitives of the driver could be very high level such as Conv2D. I am new to TVM, but intuitionally, the IR (output of the optimization) could be of lower level than Conv2D like primitives. If that's going to be the case, the graph which is composed by operators and tensors should feed to accelerator driver directly - before the IR optimization which is of lower level. @junrushao1994 If we take neural networks as program, yes I am referring to something like program slicing. I will quote the TVM stack to make my point clear. Basically we have different categories of backend devices (for intuition only):
However, this issue depends on what TVM is intended to be. If TVM is going to support only one (or very limited) non-CPU backend devices when executing one given networks, I think a context based approach is cool - we only need to fallback to CPU. Otherwise, if TVM aims to schedule ONE network (divided into sub-networks) across different devices, I guess the subgraph approach? The answer is really deeply tighten with TVM's path. There is no better or worse, there will only be the more suitable. If the decision is that TVM is going to supported only limited devices for a specific network running routine, @tqchen 's approach may come in charge. And, to be honest, though I am more likely to be interested in subgraph approach, I am still wondering that whether scheduling networks across devices is really a must in practice - first we don't have so many devices on one machine, second the memcpy could be heavy. Anyway, thanks you guys for be so patient as I really don't know much about TVM while still talking too much :) |
|
To be clear, the simple context-based approach works for multiple devices mentioned by @jackwish , including cases that do not fall back to CPU. What we can do is to annotate the context for each node. The only "drawback" of not introducing subgraph abstraction is that subfunction might be helpful to do things with recursion(which we do not consider). Note that even if we introduce subgraph abstraction, from high level point of view, the master graph that executes different subgraph still have to handle different device context(which falls back to the context-based approach) |
|
@tqchen Yes, the execution can be done on different devices for both solution. Device drivers don't need to know the context semantic as it receives a graph and execute it in the subgraph approach. A subgraph approach is not necessarily to have a recursion behavior. Say, we get a graph, we partition it into several subgraphs - the module, which holds subgraphs, is simply an executor. The master graph and subgraphs are described in the same way, and master graph doesn't knows there are many subgraphs. The executor has the executing context - there could be one subgraph or multiple subgraphs. For each subgraph, executor feeds to device driver directly. I am talking about how people stack software in a system. For both solutions, a layer that translates TVM's representation to driver representation is required (assume that the driver has generic NN interface that targets many frameworks and runtime). Context approach needs to translate context to something like subgraph and feeds the subgraph; subgraph approach feeds subgraph. See, the question is where you put the representation translation - delay it before drivers (context), or at early stage (subgraph). Btw, with respect, I am just making my point to be properly understood. Both are cool solutions. Many thanks to @tqchen and the contributors :) |
|
Good discussion and contributions are always welcomed @jackwish |
|
Thanks for all inputs. After more discussions, we think it would be more convenient for runtime to take a single graph because 1) there are usually not that many devices on a single machine in practice, 2) compiling each subgraph and executing them individually would require the construction of the subgraphs in a way to keep their correct execution order. It does complicate the design and runtime. We've started a discussion thread with some concerns at https://discuss.tvm.ai/t/graph-partitioning/504 Thank you very much for any comment and suggestion. |
|
In the context of TVMContext passed to graph runtime and with heterogeneous we are now passing a vector of TVMContext. As I understand TVMContext is tightly coupled with compiled function. Ref #1695
Hence I don't see why we need to pass TVMContext to graph runtime if storage already mapped to device_id. Am I missing any thing here ? Or Is this vector of TVMContext is a backup plan to support a future version of Heterogeneous execution where
|
|
The context is passed to map the virtual device index(which is already in the plan) to the specific context. This can still be useful say we compiled a GPU module and we can map it to gpu(0) or gpu(1) during runtime |
|
closed by #1695 |
Problem
The current graph runtime assumes that all the op are on a single context (OpenCL, or ARM), in reality we usually need switch between devices, especially for last few layers in detector models, where it might be hard to get a GPU version of the detector operators (@Laurawly is working on one, but that is a different story). A better solution would be enable the graph runtime and builder to split the graph into multiple devices, and insert copy operator when necessary.
Steps of Changes
Proposed API Changes
Related Issues
#1242
The text was updated successfully, but these errors were encountered: