Unicode and newline characters break totable #71
Comments
|
Some additional investigation by @amling and me has yielded this:
(also maybe That first one will make the input streams be read as utf8, which should fix the ellipsis encoding issue (still need to handle new lines) |
|
Yeah, I've worked around UTF-8 safeness of recs before using Note that
|
|
Hello. I am a Japanese user. The other day, I encountered what might be same root of the problem. The value of the CORE::length might be different from the width. You can get the width of the utf8 in module called AAA. I am sure that the work well in the patch below. # diff -u /usr/local/lib/perl5/site_perl/App/RecordStream/Operation/totable.pm.orig /usr/local/lib/perl5/site_perl/App/RecordStream/Operation/totable.pm
--- /usr/local/lib/perl5/site_perl/App/RecordStream/Operation/totable.pm.orig 2016-04-16 16:13:42.948118000 +0900
+++ /usr/local/lib/perl5/site_perl/App/RecordStream/Operation/totable.pm 2016-04-16 16:20:05.791268000 +0900
@@ -41,6 +41,12 @@
$this->{'CLEAR'} = $clear;
}
+use Encode;
+use Text::VisualWidth::PP;
+sub _length {
+ Text::VisualWidth::PP::width( utf8::valid($_[0]) ? decode_utf8($_[0]) : $_[0] );
+}
+
sub stream_done {
my $this = shift;
@@ -58,14 +64,14 @@
push @$fields, $field;
}
- $widths{$field} = max($widths{$field}, length($this->extract_field($record, $field)));
+ $widths{$field} = max($widths{$field}, _length($this->extract_field($record, $field)));
}
}
my $no_header = $this->{'NO_HEADER'};
if(!$no_header) {
foreach my $field (keys(%widths)) {
- $widths{$field} = max($widths{$field}, length($field));
+ $widths{$field} = max($widths{$field}, _length($field));
}
}
@@ -164,9 +170,9 @@
}
if ( (! $this->{'SPREADSHEET'}) &&
- (length($field_string) < $widthsr->{$field})) {
+ (_length($field_string) < $widthsr->{$field})) {
- $field_string .= " " x ($widthsr->{$field} - length($field_string));
+ $field_string .= " " x ($widthsr->{$field} - _length($field_string));
}
if($first) {
Please use you were probably used. |
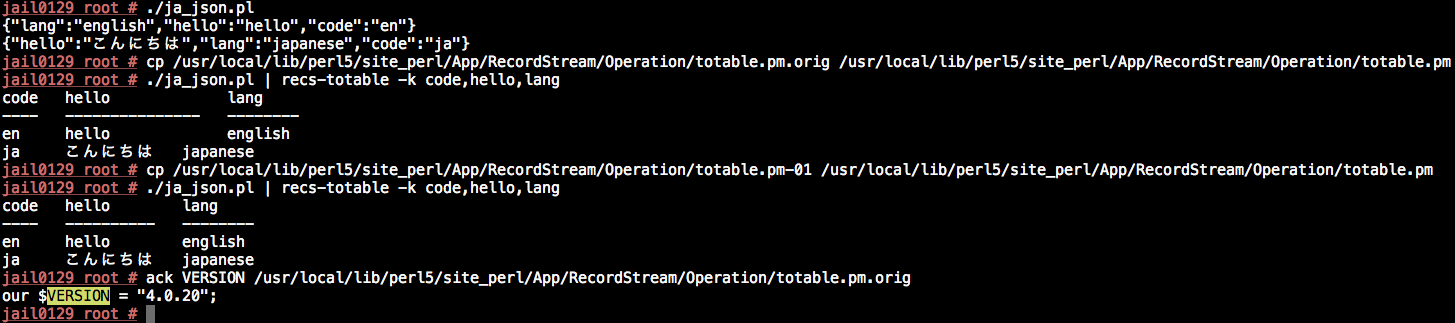
|
Awesome! thanks for the patch @bokutin I'll try to get it into master soon (needs tests too), or if you want feel free to provide a pull request. Very much thanks for the contribution |
|
A note here for later: this certainly also affects toptable |
|
Unfortunately the patch above is fixing a symptom, not the root cause. The root cause is that recs doesn't decode/encode its input/output streams and instead treats them as bytes. This is why Additionally, using the utility functions inside the The proper solution is to consistently decode/encode I/O within all of recs, most likely in one of the top-level stream classes. Requiring I/O be UTF-8 is not unreasonable this day in age, and folks can either explicitly convert when passing to recs or recs could gain a global To learn more about Unicode and Perl, I highly suggest reading Tom Christiansen's Perl Unicode Essentials talk. |
|
Yeah, good point, I was going to try your suggested route first, and it -Ben On Thu, May 26, 2016 at 9:44 AM Thomas Sibley notifications@github.com
|
|
Nod. The patch may fix the specific case presented, but it introduces other bugs due to treating Perl's internal SV state as a "UTF-8 sniffer." I don't recommend applying it even for the short term. |
|
However! Text::VisualWidth::PP may still be useful, and I'm glad @bokutin mentioned it. :-) |
|
Yep, agreed on both points, you're obviously the encoding expert here :) On Thu, May 26, 2016 at 9:50 AM Thomas Sibley notifications@github.com
|
|
Yes, my patch I think that it is shortsighted. On the other hand, in order to resolve correctly, it may be difficult.
I may wish to prepare the App::RecordStream::Operation::totable::UTF8 for myself. |

|
Your screenshot with Encode misunderstands how string literals work in Perl. You need to Look at this example which compares characters to characters: it decodes a byte-string on the left hand side and declares string literals as UTF-8 characters on the right hand side: Encodings must always be handled explicitly. Handling them implicitly is a recipe for bugs and confusion. APIs must declare if they deal in characters (i.e. decoded bytes) or in bytes (i.e. encoded characters). For recs and other tools, the sanest choice is picking a default that will cause the least amount of surprise for as many users and allowing users who need something other than the default to change it. In this case, I'm suggesting recs default to doing UTF-8 I/O and provide CLI options (+ environment vars?) to change that default. |
|
Thank you for you pointed out. I agree to the tsibley's suggestions. (^ ^) If the impact of the encoding is also like to recs-grep and recs-eval |
|
Any Perl snippets that recs evaluates will likely get an implicit |
When characters like '…' and newlines are in an outputted column, the columns no longer line up. Should probably transform the output or something an also leave a --no-escape option or similar...
Probably also affects toptable. I think those are the only two that require text alignment...
copy from irc discussion:
The text was updated successfully, but these errors were encountered: