运行原理
fis的编译过程可以分为两个阶段: 单文件编译 和 打包。处理流程如下图
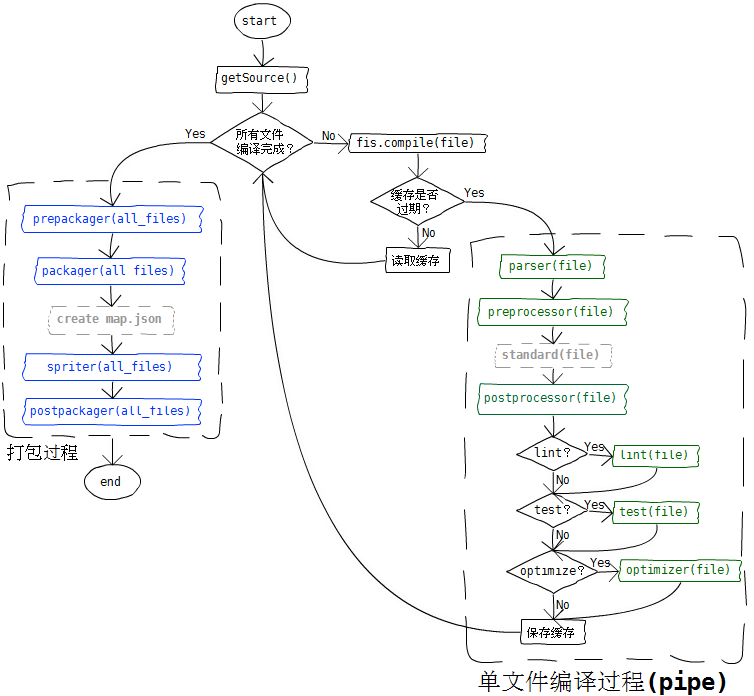
单文件编译过程 ( 源码 )
该过程对每个文件采用管道式处理流程,并在最开始处建立缓存,以提升编译性能。每个文件的处理过程又可细分为:
- parser(编译器):将其他语言编译为标准js、css,比如将前端模板、coffee-script编译为js,将less、sass编译为css。
- preprocessor(标准预处理器):在fis进行标准化处理之前进行某些修改,比如 支持image-set语法的预处理插件
- standard(标准化处理):前面两项处理会将文件处理为标准的js、css、html语法,fis内核的标准化处理过程对这些语言进行 三种语言能力 扩展处理。这也就意味着,使用less、coffee等语法在fis系统中一样具备 资源定位、内容嵌入,依赖声明 的能力。该过程 不可扩展。
- postprocessor(标准后处理器):对文件进行标准化之后的处理,比如利用依赖声明能力实现的 js包装器插件,可以获取js文件的依赖关系,并添加define包装。
- lint(校验器):代码校验阶段,使用 fis release命令的 --lint 参数会调用该过程。
- test(测试器):自动测试阶段,使用 fis release命令的 --test 参数会调用该过程。
- optimizer(优化器):代码优化阶段,使用 fis release命令的 --optimize 参数会调用该过程。fis内置的fis-optimizer-uglify-js插件和fis-optimizer-clean-css插件都是这类扩展。
打包过程 ( 源码 )
fis的打包概念和传统编译工具 概念上有很大区别,如果为了实现简单的文件合并,可以使用三种语言能力中的 内容嵌入 能力来实现,比如创建一个aio.js,里面写上对需要合并的文件的内容嵌入语法:
__inline('a.js');
__inline('b.js');
__inline('c.js');编译之后得到
//a.js content;
//b.js content;
//c.js content;而fis的打包概念实际上是 资源备份。fis在打包期间最重要的生成物是 map.json,当使用fis release命令添加 --pack 参数时,会触发打包过程,此时,会根据fis-conf.js中的 pack 节点配置将文件进行合并,然后把合并后的打包文件相关信息记录到map.json中,并生成相应文件。所以fis的打包结果并 不会再嵌入到某个文件内,而是利用map.json中的数据进行运行时打包信息查询。举个栗子:
- fis-conf.js中配置:
fis.config.merge({
pack : {
'aio.js' : ['a.js', 'b.js', 'c.js']
}
});- 执行命令 fis release --pack --dest ./output
- 进入output目录,查看map.json文件,得到内容:
{
"res" : {
"a.js" : {
"uri" : "/a.js",
"type" : "js",
"pkg" : "p0"
},
"b.js" : {
"uri" : "/b.js",
"type" : "js",
"pkg" : "p0"
},
"c.js" : {
"uri" : "/c.js",
"type" : "js",
"pkg" : "p0"
}
},
"pkg" : {
"p0" : {
"uri" : "/aio.js",
"type" : "js",
"has" : ["a.js", "b.js", "c.js"]
}
}
}- 将map.json交给某个前端或后端框架,当运行时需要“a.js”资源的时候,该框架应该读取map.json的信息,并根据一定的策略决定是否应该返回“a.js”资源所标记的“p0”包的uri。
再次强调,在fis系统内, 打包只是资源的备份,这样做的原因有:
- 如果打包生成资源通过配置再嵌入到已处理过的文件内,会导致编译的性能快速下降,可能会间接影响md5戳的准确性,甚至造成编译过程的死循环。
- fis的嵌入内容语言能力已经提供了简单的内容合并功能,如果不想使用fis的打包方案,可以使用这种方式来合并文件
- 可以运行时控制资源输出策略。fis团队 强烈推荐 使用线下生成打包资源文件,运行时决定是否输出打包后的资源这样的策略。这样做好处很多:
- 框架非常容易实现通过外部参数来切换输出打包/不打包资源策略,方便工程师线上调试。资源加载框架可以根据url的get参数或者cookie之类的外部变量来切换在查找资源时是否关心资源打包的情况。这意味着,工程师可以很方便的在浏览线上页面时让整个页面的资源都分开输出,从而快速定位问题。
- 可以有效监控资源加载情况,为自适应网站系统设计做基础。由于资源都是通过前端或者后端框架查map.json表来加载,因此可以通过统计框架的这个接口来统计线上静态资源的访问情况,从而自动生成打包配置,让网站能自动进行性能优化,无须人工干预。
- 能全局控制资源加载方式,并且很好的管理依赖,解决去重、调序等问题。资源通过框架查表获得之后,框架可以做适当的调整甚至处理,以达到性能优化的目的,自由切换PIPE_LINE、QUICKLING、NO_SCRIPT等页面输出模式,并且对工程师完全透明。
- 细粒度控制资源使用,防止出现某个包太大,不能删减的情况。比如传统的合包方式,由于难以统计合包后的资源的使用情况,导致合并的资源中即使出现了不再使用的资源也不敢删除的情况。合并的资源越来越大,冗余越来越多。fis的合包概念只是资源的备份。哪怕把所有包都删除了,资源大不了是独立输出的而已,不会出现丢失的情况。
fis系统的打包过程提供了4个可扩展的处理过程,它们是:
- prepackager(打包预处理器):在打包前进行资源预处理。
- packager(打包处理器):对资源进行打包。默认的打包器就是收集资源表,建立map.json的过程
- spriter(csssprite处理器):对css进行sprites化处理
- postpackager(打包后处理器):打包之后对文件进行处理,通常用来将map.json转换成其他语言的文件,比如php