{kind=link}
{kind=link}
{kind=link}
{kind=link}
The IBM Data Science team built a dataset with fictional information about IBM employees and wether they left the company or not. The dataset can be found here.
This project aims to train different classifcation models and predict wether an employee might leave the company or not. In the end, the projects are compared based on their recall score, where the best model is the one with highest score.
For this project, several steps in data preprocessing were followed in order to have a dataset ready for the classification models, some of which were:
Columns with high correlation between each other need to be remove so that we can remove bias from our models. The heatmap helps identify those columns.
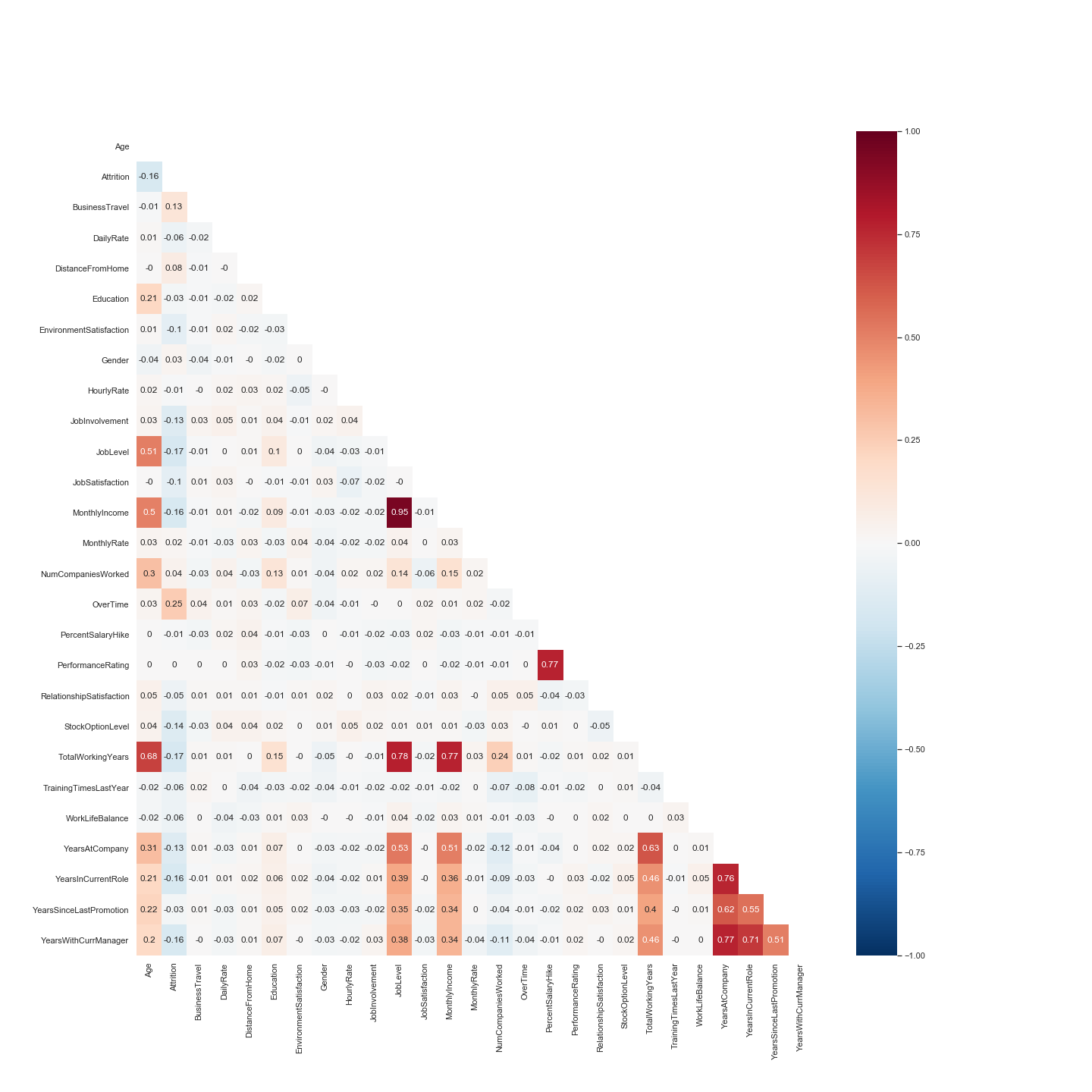
Thanks to the heatmap, we can see that the columns JobLevel and MonthlyIncome have high correlation. Since MonthlyIncome could still have importance to explain our results, the column JobLevel was dropped.
Another good approach is to standardize the variables to reduce the weight and influence that variables with bigger ranges of values might have on the models' results.
This was the distribution of each variable after standardization was applied:
The models that were used to train the dataset were the following:
- Logistic Regression;
- Logistic Regression with Feature Selection (SFS, SBS and RFE),
- Decision Tree;
- Random Forest;
- KNN;
- AdaBoost;
- XGBoost;
- CatBoost
After training and testing the models, the one with highest recall score was the Logistic Regression with SFS, with a score of 99.35%