Graphics Virtualization XenGT
Author: Kevin Tian (kevin.tian@intel.com)
Background
The Graphics Processing Unit (GPU) has become a fundamental building block in today’s computing environment, accelerating tasks from entertainment applications (gaming, video playback, etc.) to general purpose windowing (Windows* Aero*, Compiz Fusion, etc.) and high performance computing (medical image processing, weather broadcast, computer aided designs, etc.).
Today, we see a trend toward moving GPU-accelerated tasks to virtual machines (VMs). Desktop virtualization simplifies the IT management infrastructure by moving a worker’s desktop to the VM. In the meantime, there is also demand for buying GPU computing resources from the cloud. Efficient GPU virtualization is required to address the increasing demands.
Enterprise applications (mail, browser, office, etc.) usually demand a moderate level of GPU acceleration capability. When they are moved to a virtual desktop, our integrated GPU can easily accommodate the acceleration requirements of multiple instances
GPU Background
Let’s first look at the architecture of Intel Processor Graphics:
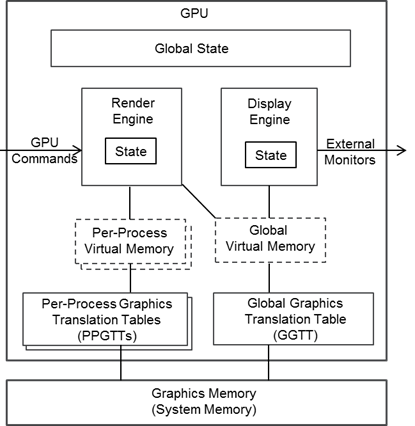
The render engine represents the GPU acceleration capabilities with fixed pipelines and execution units, which are used through GPU commands queued in command buffers. The display engine routes data from graphics memory to external monitors, and contains states of display attributes (resolution, color depth, etc.). The global state represents all the remaining functionality, including initialization, power control, etc. Graphics memory holds the data, used by the render engine and display engine.
The Intel Processor Graphics uses system memory as the graphics memory, through the graphics translation table (GTT). A single 2GB global virtual memory (GVM) space is available to all GPU components through the global GTT (GGTT). In the meantime, multiple per-process virtual memory (PPVM) spaces are created through the per-process GTTs (PPGTTs), extending the limited GVM resource and enforcing process isolation.
Graphics Virtualization Technologies
Several technologies achieve graphics virtualization, as illustrated in the image below, with more multiplexing on the left, and higher performance on the right.
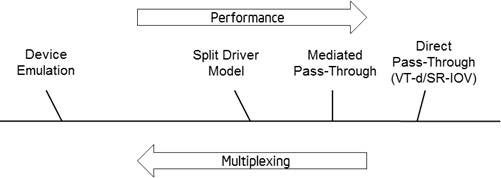
Device emulation is mainly used in server virtualization, with emulation of an old VGA display card. Qemu 1 is the most widely used vehicle. Full emulation of a GPU is almost impossible, because of complexity and extremely poor performance.
The split driver model implements a frontend/backend driver pair. The frontend driver forwards high-level DirectX/OpenGL API calls from the VM to the backend driver in the host through an optimized inter-VM channel. Multiple backend drivers behave like normal 3D applications in the host, so a single GPU can be multiplexed to accelerate multiple VMs. However, the difference between the VM and host graphics stacks easily leads to reduced performance or accuracy. Because it is hardware-agnostic, this is the most widely used technology, so far. Actual implementations vary, depending on the level where forwarding happens. For example, VMGL 2 directly forwards GL commands, while VMware vGPU 3 presents itself as a virtual device, with high-level DirectX calls translated to its private SVGA3D protocol. Another recent example is Virgil 6, with its experimental virtual 3D support for QEMU.
Direct pass-through, based on VT-d 4, assigns the whole GPU exclusively to a single VM. When achieving the best performance, it sacrifices the multiplexing capability. The PCI SR-IOV 5 standard allows a GPU to be assigned to multiple VMs by implementing hardware multiplexing. However, no GPU vendor has considered the SR-IOV extension because of hardware complexity.
Mediated pass-through extends direct pass-through, using a software approach. Every VM is allowed to access partial device resources without hypervisor intervention, while privileged operations are mediated through a software layer. It sustains the performance of direct pass-through, while avoiding the hardware complexity introduced in the PCI SR-IOV standard. However, in-depth GPU knowledge is required for a robust mediated pass-through architecture, so this technology is largely co-driven by GPU and VMM vendors. XenGT adopts this technology.
XenGT
XenGT implements a mediated pass-through architecture, as illustrated below, running a native graphics driver in VMs to achieve high performance. The ability to accelerate a native graphics stack in a VM minimizes the virtualization overhead and also alleviates the tuning effort.
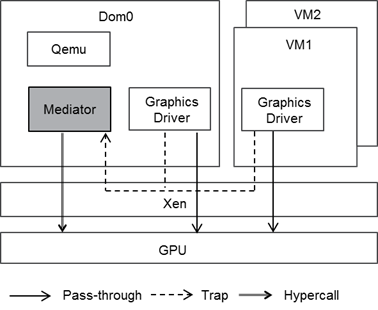
Each VM is allowed to access a partial performance critical resource without hypervisor intervention. Privileged operations are trapped by Xen and forwarded to the mediator for emulation. The mediator creates a virtual GPU context for each VM, and emulates the privileged operations in the virtual context. Context switches are conducted by the mediator when switching the GPU between VMs. XenGT implements the mediator in dom0. This avoids adding complex device knowledge to Xen, and also permits a more flexible release model. In the meantime, we want to have a unified architecture to mediate all the VMs, including dom0, itself. So, the mediator is implemented as a separate module from dom0’s graphics driver. It brings a new challenge, that Xen must selectively trap the accesses from dom0’s driver while granting permission to the mediator. We call it a “deprivileged” dom0 mode.
Performance critical resources are passed through to a VM:
- Part of the global virtual memory space
- VM’s own per-process virtual memory spaces
- VM’s own allocated command buffers (actually in graphics memory)
This minimizes hypervisor intervention in the critical rendering path. Even when a VM is not scheduled to use the render engine, that VM can continuously queue commands in parallel.
Other operations are privileged, and must be trapped and emulated by the mediator, including:
- MMIO/PIO
- PCI configuration registers
- GTT tables
- Submission of queued GPU commands
The mediator maintains the virtual GPU context based on the traps mentioned above, and schedules use of the render engine among VMs to ensure secure sharing of the single physical GPU.
There are many challenges to be tackled in the actual implementation. We may cover the interesting techniques in a future newsletter.
References
- 1 Qemu, http://www.qemu.org
- 2 VMGL, http://sysweb.cs.toronto.edu/vmgl
- 3 VMware vGPU, http://labs.vmware.com/academic/publications/gpu-virtualization
- 4 VT-d, http://software.intel.com/en-us/articles/intel-virtualization-technology-for-directed-io-vt-d-enhancing-intel-platforms-for-efficient-virtualization-of-io-devices
- 5 SR-IOV, http://www.pcisig.com/specifications/iov
- 6 Virgil, http://www.phoronix.com/scan.php?page=news_item&px=MTQxNDY
*Other names and brands may be claimed as the property of others.